
「Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation」LLM評価専門の小型LLMについて
Googleが発表した新たなLLM「FLAMe」に関する論文の解説です。
Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation
論文の内容まとめ
・LLMの性能評価が大変になってきた
・LLM性能を自動で評価するためのLLM「FLAMe」を作った
・24Bパラメータでありながら一部ベンチマークでは全ての既存モデルを上回った
つまり、GoogleはLLMのモデル性能を評価するための専門的なモデル「FLAMe」を開発し、それが目的の領域・・・"LLMの性能を評価するLLMとしての性能の評価"でGPT-4oをも超える高い性能を達成したということです。
あくまで専門領域でのみ上回ったという話ではありますが・・・
それにしても、仮に特定のタスクであれ、たった24Bに過ぎないパラメータ数のモデルが本当に現行での最高性能を達成したというなら驚くべきことですよね。
それでは以下、解説に入ります。
始まり
大規模言語モデルが進歩するにつれ、その性能を評価するコストはますます大きくなっています。
人間が直接モデルのパフォーマンスを評価することは良い手段でしょうが、それはあまりに高コストなうえに個々人の主観による評価のばらつきが発生してしまいます。
その点で言語モデル自体にあるモデルの性能評価を行わせるというのは良い解決策です。コストは低く、評価基準も常に一定となるはず。
そんなわけでGoogleはこの目的のための専門的なモデル・・・つまりLLM評価用LLMの開発に着手しました。
問題
目標に向けて、いくつかの重大な問題がありました。
LLM自動評価用LLM(原文ではLLM autoraters, 以下"評価用LLM" )をトレーニングして人と同様の判断を下せるようにするためには、当然そのための元データ・・・膨大な人間による判断の記録が必要です。
過去の研究からそれを収集することは有望に思えるものの、各データの形式は標準化されておらず、評価基準も多様で、そのうえ文書化が不十分であったり権利関係の懸念も考えられます。
LLMサービスの中には出力を他モデルの開発に使用することを禁止しているものもあります(例えばOpenAIのLLMは学習データ生成目的での利用禁止)。
対処
上記の問題に対処するため、Googleは先行する関連研究を徹底的に調査し、時には著者と相談し、膨大なコストをかけて得た大量の人間の評価の記録にこれまた膨大なコストをかけて文書化・標準化を行ったようです。
そうして「権利的に透明な合計530万件、102の品質評価タスクの記録」であるFLAMeを作成しました。言語の翻訳や指示への正確な対応など、さまざまなタスクタイプを網羅しているとか。
こうしてGoogleは評価用LLMの学習に役立つかもしれない強力なデータを手に入れました。後は実際に学習を行って、どうなるか。
学習
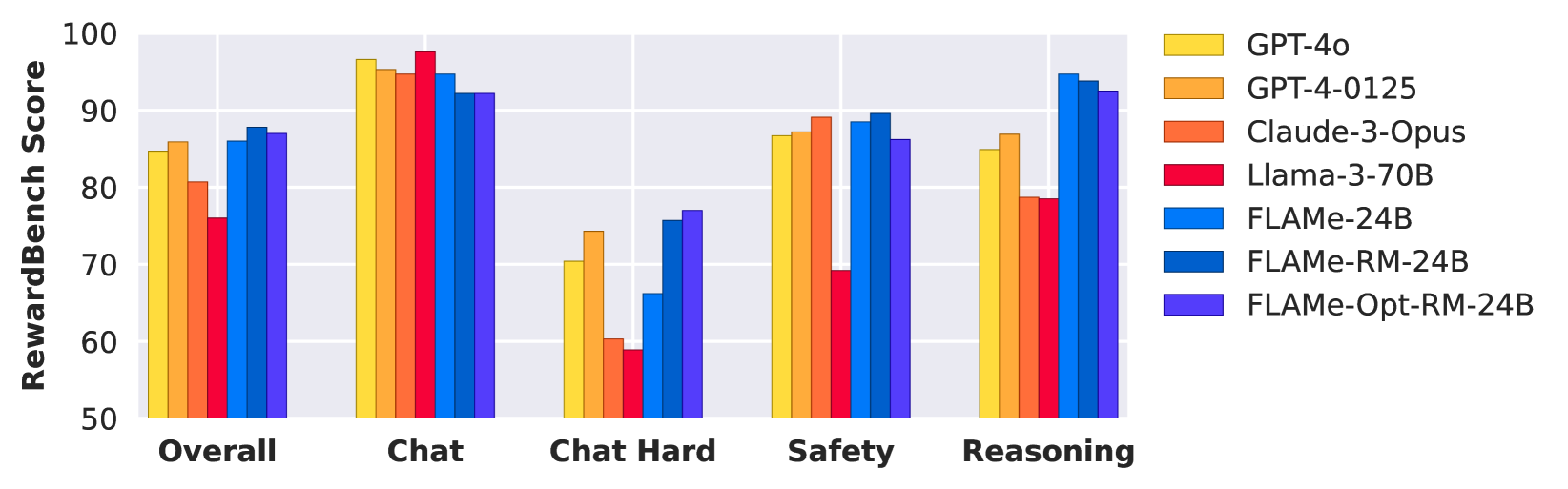
https://arxiv.org/html/2407.10817v1#S1.F1より
1.まずGoogleはかつて開発したPALM-2-24Bを上記のFLAMeでトレーニングしました。この時点で大きく改善し、多くのタスクでGPT-4, Claude-3, Llama 3といった最新の大型モデルを上回りました。
2.次いでこのFLAMeモデルに対して、報酬モデル評価タスクの性能向上を目的とした追加のファインチューニングを行いました。結果としてできたFLAME-RM 24BモデルはRewardBenchベンチマークでの性能が86.0から87.8へと改善されました。
3.更にもう一つ、異なる方法でPALM-2-24Bを学習させたFLAMe-Opt-RMも作りました。今までにない新たなテイルパッチファインチューニング技術?(novel tail-patch fine-tuning technique)を用いて、データセットの最適な割合を決定したうえでPALM-2-24Bをファインチューニングしたものです。こちらもまたRewardBenchにて87.0と高いスコアを得たうえ、この手法では1.のFLAMeに対して1/25の量のデータしか用いていません。
結論
1.100以上の品質評価タスクについての、標準化された500万件のデータセットを作成した。そしてこれは公開される。
2.全ての一般的な独自LLMよりも優れた評価用LLMを開発した。そのトレーニング方法の有効性を実証した。
3.計算効率の高いマルチタスクトレーニングの手法を導入した。


Comments